
Data Science sits at the core of any analytical exercise conducted on a Big Data or Internet of Things (IoT ) environment. Data science involves a wide array of technologies, business, and machine learning algorithms. The purpose of data science is just not doing machine learning or statistical analysis but also to derive insights out of the data that a user with no statistics knowledge can understand. In a fast paced environment such as Big Data and IoT where the type of data might vary over the course of time, it becomes difficult to maintain and recreate the models each and every time.
This gap calls up for an automated way to manage the Data Science algorithms in those environments. The rise of data science was to move away from a rule-based system to a system where a machine learn rules by itself for its automation. Machine learning makes data science inherently partially automated. The other half which needs manual intervention is still to be automated. However, those are the areas which involve the experience and wisdom of a data scientist, a business expert, a software developer, a data integrator, each and everyone who currently contribute to making a data science project operational. This makes it difficult to automate each and every aspect of it. However, we can think of data science automation as a two-level architecture wherein:
Level-1: Different data science disciplines/components are automated.
Level-2: All the individual automated components are interconnected to form a coherent data science system.
We can think of an automated data science system capable enough to articulate us our problem whenever we throw a data set to it. Also, it should be intelligent enough to provide us with all possible solutions in a language which we can understand. We can imagine data preparation, machine learning, domain knowledge, and result interpretation as four major tasks required to execute a data science project successfully. All these tasks have to be converted to automated modules to create an automated data science system.
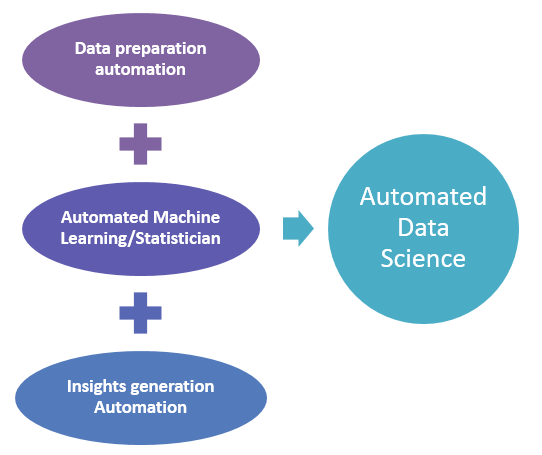
Data preparation automation: Data preparation is a repetitive task that has to be done every time while creating models. Data extraction, data cleaning, and data transformations such as imputing null values and algorithm specific transformations are some tasks which fall into this category. Many organizations have adopted to automate these tasks and branded the engine as a data science automation tool. However, most of these tools use rule-based logic for automating the data preprocessing tasks. A question: Do we need rule-based systems to automate data science? Well, No. We need data preprocessing automated by machine learning itself. For example, the decision to choose what all preprocessing function has to be applied on the data for a problem are to be learned by machines themselves.
Feature engineering is an another area of data preparation which requires automation. Feature engineering is a technique to convert raw data into attributes/predictors that contribute to improving the accuracy of a machine learning project. Feature engineering automation is still at a nascent stage and an active area of research. Incredible progress is made by data scientists from MIT on developing a “Deep Feature Synthesis” algorithm capable of generating features from raw data.
Automated Machine Learning/Statistician: This is an area of data science automation where statistical routines and machine learning are automated. The system executes the best algorithm based on the provided data set. It hides the intricacies and mathematical complexity of algorithms from the user making it available to masses. The user needs to provide automated statistician with data. It understands the data, creates different mathematical models and returns the result based on a model that best explains the data. Automated Statistician is a complex science as it requires the system to learn the input data patterns, find the best fit values and self-optimize its parameters using several statistical and machine learning algorithms. This requires the generalization of various algorithm constraints and enormous computing power.
Automated machine learning is gradually maturing by leveraging cloud-based servers to manage the requirement for high computational power. Organizations creating data products are progressively including features such as meta-learning, a process of automatically selecting a suitable machine learning algorithm based on the metadata of the data set. Also, there has been a breakthrough of bringing Neural Networks and Deep Learning to mainstream for automated data science tasks. Some of the niche Artifical Intelligence startups like H2O.ai are the forerunners of creating in-memory optimized deep learning and machine learning algorithms, generalized model building process by introducing several built-in functionalities and providing many model tuning options such as hyperparameter tuning which support to have greater control over the algorithms. Hyperparameter tuning is a process to automate the trial and error of re-running the machine learning models several times to decide the appropriate parameters for a model on a data set.This helps in automating data science process to a certain extent and make data scientists free from cumbersome process of testing the models with different parameters.
Insights generation Automation: Results out of a data science project are not useful until and unless a business user or an audience with no statistics knowledge comprehends it. The cream of a data science activity is the story telling part where a data scientist explains the results to people in a comprehensive and transparent method. Automating this task requires generating user-friendly texts automatically from the statistician friendly results. Natural Language Generation(NLG) is the current front runner framework which can help in translating machine language into a natural language. Nlgserv and simplenlg are two NLG frameworks which we can use for this task. Also, we can use Markov chains for generating sentences and for manufacturing stories automatically.
To conclude, we can say the innovation for data science automation has started coming into existence and will gradually evolve in years to come. We are currently at a stage where we have begun to tackle automation for individual data science modules. From here, we need to move to a more generic data science platform with all modules automated and integrated together. This is how a change starts. Just like the way, the room-sized computers with ancillary parts got transformed to tiny credit-card sized computers like Raspberry Pi.
