We come across several documents daily. It might be an electricity bill, a phone bill, a letter, or a project document. A few years back, these were all printed on paper and we got hard copies. However, now, the digital revolution has changed the print media landscape. Digitalization has increased the amount of online information, and all of this is available to us online as text.
This analogy can be extended to our daily reading materials as well. I remember buying DataQuest magazines each month to keep myself updated with technologies, cutting out the interesting pieces of the magazines, and putting them into different files for easy reference. But now, I prefer stopping by DZone to read through various articles based on what I prefer to read that day. The Zones provide a nice segregation of helpful articles based on different technologies. Similarly, we refer to various other e-magazines such as KDNuggets, Data Informed, or some other blogs. Anything that we find interesting, we bookmark it or store it as a file on our computer for later reference. For example, I have created two folders on my computer for two important technical categories I follow: big data and database. Any big data article I choose goes into my big data folder and similarily for databases. This is what we call categorization of documents or document classification/text classification. Based on our needs, each document can be in one, multiple, or no category at all.
Let’s say we want to automate this document categorization process. Any new documents that I find interesting, I put it in a folder, and a program automatically places it inside the appropriate category folder. How cool it will be! This interesting problem can be solved using machine learning. Using ML, the objective is to learn the different categories from previous examples, and this new classifier can perform the category assignments automatically.
In the previous articles in this series, we used different DZone articles to illustrate the examples. The first article in the series focused on topic modeling, which is primarily about finding essential words/terms in a collection of documents that best represent a group. The second was about clustering documents, which is about grouping documents into different homogeneous categories.
In this article, we will also be using DZone articles for demonstration. I have created two folders: Big Data and Database. Around eight articles each from the Big Data and Database Zones are extracted into these folders. The classifier will be trained and tested on this data.
Document/Text Classification Process
Preprocess the documents to convert them into word vectors. Prepare a DTM (document-term matrix) that captures the information about each term in a document. To learn more about this, refer to the previous article.
Then, transpose the DTM so that the words become the columns, and each row is the number of occurrences of a word. Convert it into to a DataFrame for better data handling. So, each instance/row in a data frame is a document. Assign labels to each row in the DataFrame.
library(tm)
#Path of the document folders
DirpathName <- "/Users/sibanjan/datascience/textmining/documentclassification"
#Individual Zone Folders for training/testing. Initially we train on articles for BigData and Database zones
SubDirectories <- c("BigData","database")
#Function to build and clean the documents
generateTDM <- function(subDir , path){
# Create complete directories by concatinating Directory and Subdirectory
dir <-paste(path, subDir, sep="/")
#create a corpus using the above full formed directory path
articles.corpus <- Corpus(DirSource(directory = dir , encoding="UTF-8"))
# make each letter lowercase
articles.corpus <- tm_map(articles.corpus, tolower)
# remove punctuation
articles.corpus <- tm_map(articles.corpus, removePunctuation)
#remove numbers
articles.corpus <- tm_map(articles.corpus, removeNumbers);
# remove generic and custom stopwords
stopword <- c(stopwords('english'), "best");
articles.corpus <- tm_map(articles.corpus, removeWords, stopword)
articles.corpus <- tm_map(articles.corpus, stemDocument);
#create TDM
articles.tdm <- TermDocumentMatrix(articles.corpus)
#remove sparse terms
articles.tdm <- removeSparseTerms(articles.tdm,0.7)
#return the results , which is the list of TDM for spam and ham.
result <- list(name = subDir , tdm = articles.tdm)
}
# Let’s write a function that can convert Term document matrix to data frame
#The folder name represents the type of article. The below funtion binds the folder name
# as a target to each document
BindtargetToTDM <- function(indTDM){
# Transpose the TDM, so that the words becomes the columns and row is the number of occurences of word
article.matrix <- t(data.matrix(indTDM[["tdm"]]))
#convert this matrix into data frame
article.df <- as.data.frame(article.matrix , stringASFactors = FALSE)
# Add the target to each row of the data frame
article.df <- cbind(article.df , rep(indTDM[["name"]] , nrow(article.df)))
#Give a name to the new target column
colnames(article.df)[ncol(article.df)] <- "ArticleZone"
return (article.df)
}
list.tdm <- lapply(SubDirectories , generateTDM , path = pathName)
article.df <- lapply(list.tdm, BindtargetToTDM)
As the target (ArticleZone) is a class variable, we need to create a classification model.
Create train and test datasets. Train the model using a supervised algorithm such as Naive Bayes. Validate the accuracy of the model using the test data.
# join both Big Data and Database Zone data frames
library(plyr)
all_article.df <- do.call(rbind.fill , article.df)
# fill the empty columns with 0
all_article.df[is.na(all_article.df)] <- 0
str(all_article.df)
target_col_position <- which(colnames(all_article.df)=="ArticleZone")
#Reorder the target and predictors
all_article.df.ordered <- all_article.df[,c(target_col_position, 1:target_col_position-1,(target_col_position+1):ncol(all_article.df))]
#Prepare training/test set
train.idx <- sample(nrow(all_article.df.ordered) , ceiling(nrow(all_article.df.ordered)* 0.7))
test.idx <- (1:nrow(all_article.df.ordered))[-train.idx]
all_article.df.train <- all_article.df.ordered[train.idx,]
all_article.df.test <- all_article.df.ordered[test.idx,]
library(e1071)
library(caret)
trainedModel <- naiveBayes(all_article.df.train[,c(2:ncol(all_article.df.ordered))],all_article.df.train[,c(1)], data = all_article.df.train)
predict.test <- predict(trainedModel, all_article.df.test)
confusionMatrix <- confusionMatrix(predict.test,all_article.df.test[,c(1)])
confusionMatrix
The accuracy is 1, i.e. the model was able to correctly classify all the test data’s categories accurately. This is too good to believe and might be a case of overfitting, as well. I assume the data was very clean, as they were prepared by selecting pieces from two very different Zones. This made the algorithm separate the essential terms and create a suitable classifier correctly. However, we can increase the data size, pick different samples to prepare another dataset, and create another model. Model building is an iterative process, and we continue until we (people) and they (algorithms) are somewhat satisfied with the results. For now, let’s hold onto this model.
Let’s think for a while that DZone liked this model and deployed it in their production environment. Now, when an author submits a new article, it will be assigned to a new Zone automatically.
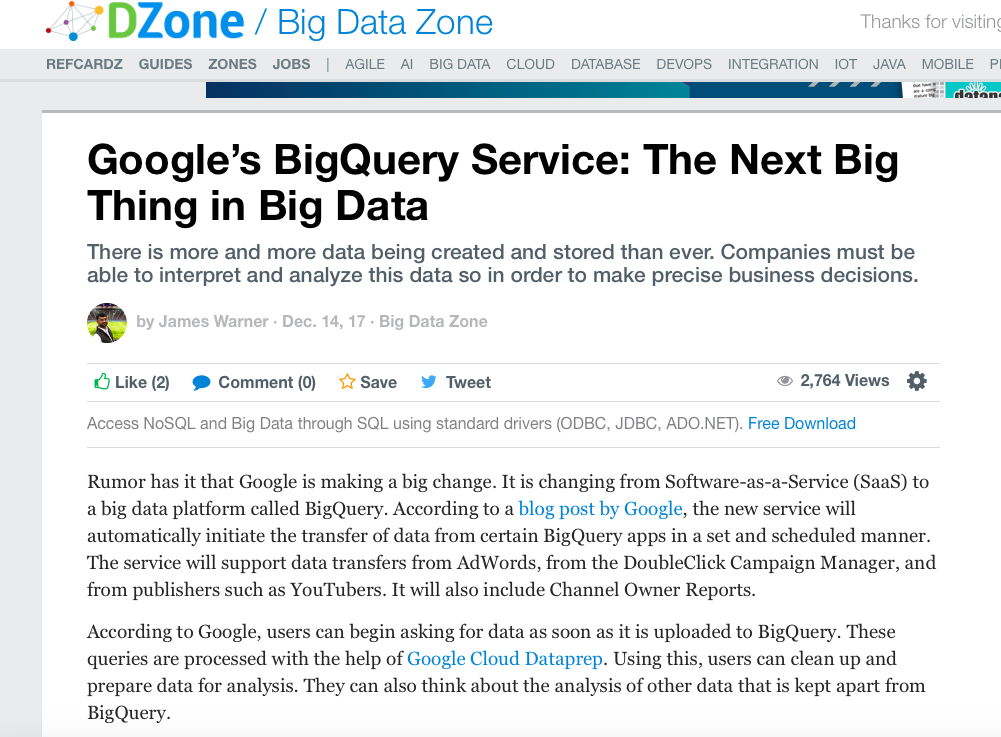
To illustrate this scenario, I picked up the below article by James Warner and kept it inside a “New” folder. Any new uncategorized article goes into this “New” folder.
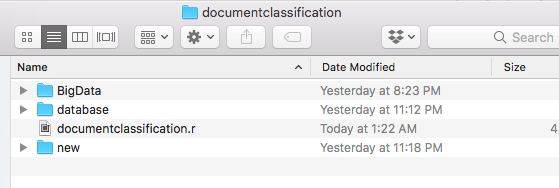
I ran the below code to predict the article category.
tdm.new <- lapply("new" , generateTDM , path = pathName)
DataFrame.new <- lapply(tdm.new, BindtargetToTDM)
predict_new <- predict(trainedModel, DataFrame_new)
as.character(predict_new)

And it correctly predicted it to be a Big Data Zone article. Now with this classifier, DZone can save time and eliminate the manual effort by automating the Zone assignment problem.
You can find the code and data for this example on my GitHub.
