The use of Machine Learning is growing widespread. Organizations are embracing it in various ways to improve their businesses. The rise of Machine Learning is coupled with the advance of open source big data processing frameworks which makes it possible to analyze tons of data in a cost-effective and efficient way. Apache Spark is one of those frameworks which have grown as a blue eyed technology in this Big Data processing world.
Apache Spark provides two libraries- MLlib and ML Pipeline for implementing machine learning. Traditionally, MLlib was the only machine learning library in Apache Spark. However, Mllib just provides machine learning algorithms that are used to create models. The creation of machine learning models is not merely applying the machine learning algorithms to data. Creating a machine learning model involves several stages of data preparation, post-processing, and validations. Data traverses through different steps before delivering back the results to us. Managing this ML workflow is a cumbersome process.
With the introduction of ML pipelines in Apache Spark, it is now easier to handle the machine learning workflow. ML pipelines bind the different steps of an ML flow together making it efficient to prepare and deploy the models in a production environment.
Below is a list of few important terminologies associated with ML Pipelines:
1) A DataFrame is used as data sets in an ML pipeline. A dataframe can be used to store various types of data types together in different columns. It can be created from existing RDD’s, data files or external database tables.
2)Transformers are used to transform or convert one data frame to another. For example, a transformer can read inputs, create new features(columns) by combining some inputs and output a new data frame with appending the new columns to input dataframe.
3) Estimators are the machine learning algorithms that learn from the training data. Estimators have a fit() method which is invoked to learn from the data and produces a model which is a transformer. The learned model is a transformer as it takes the input data frame, makes the predictions and creates a new data frame by adding new prediction columns to the existing data frame. For example, DecisionTreeClassifier is an estimator which accept a training Dataframe and produces a DecisionTreeClassification Model which is a transformer.
4) A Pipeline chains together multiple stages such as data preparation, model training and post processing tasks of the machine learning workflow together. It consists of a collection of stages where each stage is either an Estimator or a Transformer. The transformers and estimators are specified in a sequence to form a machine learning workflow. During the execution phase, these stages run in the order they are defined. Also, with the help of the pipeline API, it is easier to combine and tune multiple ML algorithms into a single workflow.
5) Params provide uniform API to specify parameters for both transformers and estimators
The below example demonstrates the use of spark ML pipeline to create a decision tree model. In this example, we will create a PCA model first and then use the newly created features to create a decision tree model for predictions. PCA is a dimensionality reduction technique used to reduce the features used to represent the data.
We will use the Spark shell to build the ML pipeline and evaluate the accuracy of our model.
- First, we need to import the necessary spark.ml libraries
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.classification.DecisionTreeClassificationModel
import org.apache.spark.ml.feature.PCA
import org.apache.spark.ml.feature.{ StringIndexer, IndexToString, VectorIndexer }
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.{ DataFrame, Row, SQLContext }
- The next step is to start the SQLContext and load the data. We use the Apache Spark provided sample data “sample_multiclass_classification_data.txt”.
val sqlContext = new SQLContext(sc)
val data = sqlContext.read.format("libsvm").load("../data/mllib/sample_multiclass_classification_data.txt")
- We split the data into training(60%) and test(40%) sets. The training data set would be used to train model, and test data to evaluate the model accuracy.
val Array(trainingData, testData) = data.randomSplit(Array(0.6, 0.4))
- We can take a look at the structure of training data using the below code. The task of a machine learning model is to first learn the relationship between the “labels” and “features”.Then use this knowledge to predict the label from the features of a new data set.
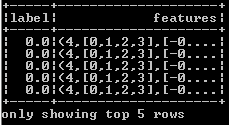
- We plan first to reduce the set of features and then create a Decision Tree with this reduced set of features. So, we define a PCA and a Decision Tree model. The input to PCA would be the “features” column, and the output would be stored in “pcaFeatures” column. The setK(2) method projects the original 4-dimensional feature vectors into 2-dimensional principal components.
val pca = new PCA().setInputCol("features").setOutputCol("pcaFeatures").setK(2)
- The output “pcaFeatures” from PCA would be used as the input features for training the decision tree model. The “label” serves as the target label to be learned.
val dt = new DecisionTreeClassifier().setLabelCol("label").setFeaturesCol("pcaFeatures")
- Next, we chain the PCA and Decision Tree in a Pipeline.
val pipeline = new Pipeline().setStages(Array(pca,dt))
- The pipeline is trained using the training data set “trainingData”.
val model = pipeline.fit(trainingData)
- Now the trained model is applied to the holdout test data set “testData”. The transform method does the same treatment on the data defined in the pipeline, does the predictions and creates a new data frame by appending the new predicted labels as a column.
val predictions = model.transform(testData)
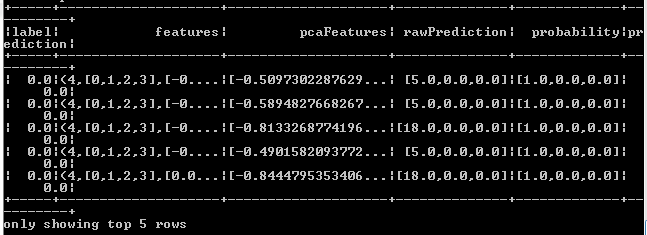
- We use the show method to view the dataframe. From the below figure, we see top 5 rows with the pcaFeatures, rawPredictions, probability and prediction columns added to the testData frame.
predictions.show(5)
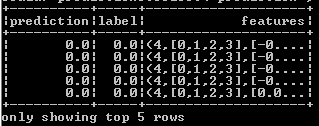
- If we want to view data of some columns selectively, then we can use the select method as shown in below Figure.
predictions.select("prediction", "label", "features").show(5)
- Use the MulticlassClassificationEvaluator to compute accuracy and misclassification error of the model
val evaluator = new MulticlassClassificationEvaluator().setLabelCol("label").setPredictionCol("prediction").setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
- Finally, inspect the metrics to evaluate the model. The model seems to be good with an accuracy of 94.6% and misclassification of 5.35%
val accuracy = evaluator.evaluate(predictions)
println("Accuracy " + accuracy*100)
println("Misclassification Error = " + (1.0 - accuracy)*100)

We saw how convenient it is to tie different machine learning steps together in an ML pipeline. Though spark.mllib package remains to be supported, the spark.ml package is suggested to be used because of the adaptability and performance benefits that it allows. You can learn more about ML pipelines from Apache Spark ML pipeline docs (http://spark.apache.org/docs/latest/ml-guide.html).
