Apache Flink is an Apache project for Big Data processing. Although it looks like Apache Spark, there are a lot of differences in both their architecture and ideas. The defining hallmark of Apache Flink is the ability to process streaming data in real time. Apache Spark is considered to be the pioneer in real-time processing with proven capabilities, but its micro-batching architecture supports a Near Real Time (NRT) scenario — Apache Flink is simply real time.
The primitive concept of Apache Flink is the high-throughput and low-latency stream processing framework which also supports batch processing. The architecture is a flip of the other Big Data processing architectures where the primary notion was the batch processing framework. This is something that organizations have been looking for over the last decade. There is a need for platforms supporting low latency data movement for applications where even a millisecond delay can lead to severe consequences. The prospect of Apache Flink seems to be significant and looks like the goal for stream processing.
“I would consider stream data analysis to be a major unique selling proposition for Flink. Due to its pipelined architecture Flink is a perfect match for big data stream processing in the Apache stack.” Volker Markl, Professor and Chair of the Database Systems and Information Management group at the Technische Universität Berlin.
The core of Apache Flink is the Runtime as shown in the architecture diagram below. We can also tell it is the Kernel of Flink which is a distributed streaming dataflow engine that provides fault tolerant data distribution and communication. The streaming dataflow engine interprets every program as a dataflow graph.
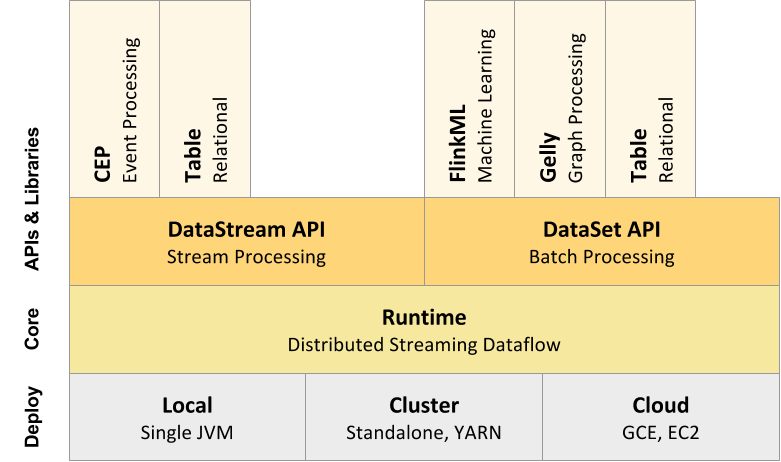
Image Credits: https://flink.apache.org/
Some of the features of the Core of Flink are:
- Executes everything as a stream and processes data row after row in real time.
- Supports iterative execution and follows a distributed data flow approach which is crucial to realize the promise of Big Data.
- The engine is versatile and allows execution of existing MapReduce or Storm applications.
- It has a cost based optimizer for both Stream and Batch processes.
- The memory management is optimized and managed automatically by the engine.
On the top of the Core, we have DataStream API for Stream processing and DataSet API for batch processing. There are also specific API and Libraries over the DatasStream and DataSet API’s described below:
- Table API enables the usage of SQL queries over the data. They are be easily embedded on both the DataStream and DataSets API’s and supports the usage of relational operators like selection, aggregations, and joins.
- Flink ML can be used for performing machine learning tasks over the DataSet API. It enables users to write ML pipelines which make it easier to handle the machine learning workflow. ML pipelines bind the different steps of an ML flow together making it efficient to prepare and deploy the models in a production environment.
- Gelly for graph processing. It provides set of operators to create and modify graphs. A graph is represented by a DataSet of edges and DataSet of vertices. Gelly is only available for DataSet API and can only be used for batch processing.
- Flink CEP is the complex event processing library for Flink. It allows you to quickly detect complex event patterns in a stream of endless data. Flink CEP is only available for stream processing over DataStream API.
Here are some key differences as told by Von Hans-Peter Zorn Und Jasir El-Sobhy:
- Stream Processing: While Spark is a batch-oriented system that operates on chunks of data, called RDDs, Apache Flink is a stream processing system able to process row after row in real time.
- Iterations: By exploiting its streaming architecture, Flink allows you to iterate over data natively, something Spark also supports only as batches.
- Memory Management: Spark jobs have to be optimized and adapted to specific datasets because you need to manually control partitioning and caching if you want to get it right.
- Maturity: Flink is still in its infancy and has but a few production deployments.
- Data Flow: In contrast to the procedural programming paradigm Flink follows a distributed data flow approach. For data set operations where intermediate results are required in addition to the regular input of a transaction, broadcast variables are used to distribute the pre-calculated results to all worker nodes.
Apache Flink is not as familiar as Apache Spark as it is relatively new and production deployments are scanty. However, it is viewed as 4g of Big Data Analytics framework, and the reason is described in this excellent presentation by Slim Baltagi, Director of Big Data Engineering, Capital One.
