Introduction to the Series
In this brand new series — Data Science Start-Ups in Focus — we’ll deep dive into start-ups in the area of data science and analytics to learn from their unique perspectives in the field. The goal here is to introduce readers to some new helpful platforms & tools, to show companies doing interesting things related to Machine Learning & the Big Data space, and to help shine a spotlight on specific happenings in the field that we think are worth your attention.
The Current State of Data Science
While the topics of Machine Learning and Data Science are quite popular right now, the practices involved in both aren’t actually understood by most people. There are a lot of materials about these topics available on the internet that people try to use directly with their data without understanding the implications. Even if it works out for some, the use of those models in production is risky without proper setups. And even if we’re able to get things working in production, the same model probably can’t be used on a different data set. Even if we adapt to a different data set, the data laid down for a particular model can change, and we’ll have to rework the design. Understand that a data scientist is not just creating a model but finding an optimal set of parameters and features that yield better results from the model. Knowing the machine learning algorithms doesn’t make one a data scientist, but the art of arranging the blocks within those algorithms to fit with the data makes him/her one.
We hear a lot about the difficulty in finding a good data scientist. It’s not because data science is rocket science, but because few people have expertise in playing with the data. After all, it’s a relatively new field and experience is lacking. The art of creating models comes with experience and experience comes with the investment of time in doing that work. We are currently witnessing the growth of a new breed of data scientists who learn Machine Learning to leap into the young field of Data Science. This mirrors the increase of universities offering Data Science specialized courses. So we have a platform creating new data scientists… however, those professionals will take some time to develop a matured understanding of the application of ML techniques. It’s one thing to do ML in theory and another to do it in practice.
The First Platform Covered in the Series – BigML
To do Machine Learning without many data scientists and make ML accessible to all, we see a lot of innovation in Data Science platforms from leading industry players and also various startups. This month we’ll focus on BigML which was founded on the basis of making Machine Learning easy and beautiful for everyone. Machine Learning platforms like BigML can assist devs in learning the skills of data science through constraints and help them to get things going with minimal knowledge of the space.
BigML – What Is It? Why Use It? How’s It Work?
BigML provides a wide array of features within a usable webUI. Loading the data set and managing the Machine Learning pipeline is very handy and can be done with just a few clicks.
Getting started with BigML is super easy and exploring the functionalities is not a problem at all. You are free to use the platform for any tasks under 16 MB, allowing you to upload sources and build models at no charge.
Create the account using this link – BigML Create Account. After doing so, log in and you’ll see four tabs arranged in order by the typical Machine Learning execution stages. See how it looks below:
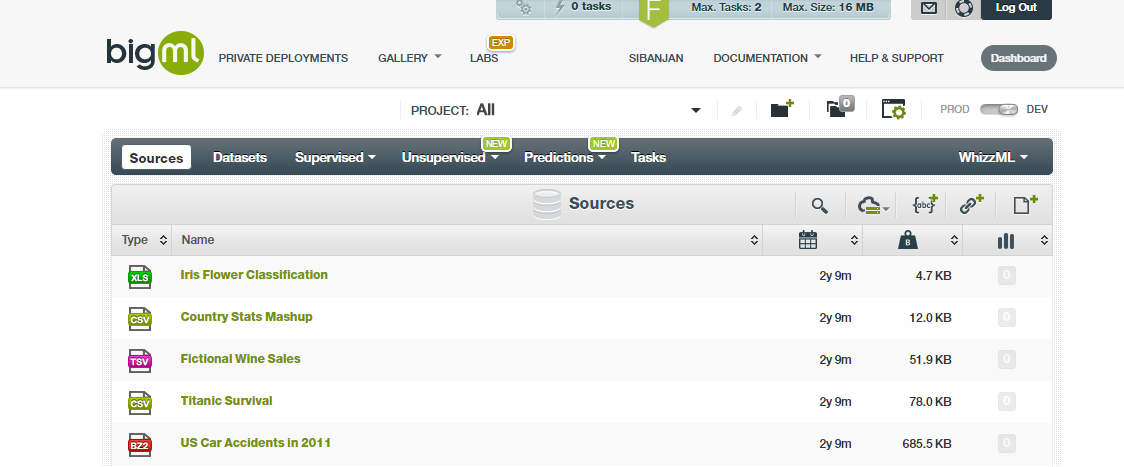
Site Map
- Sources: Used to define the data sources. There are some example data sources already present in the system which can be utilized to experiment with the platform. Also, you can use your data by defining your private data source which includes most of the Cloud storage systems, URLs, or traditional CSV files.
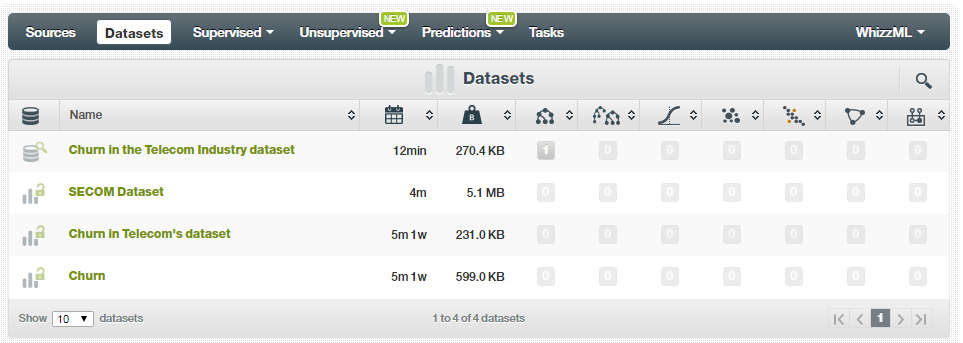
- Datasets: Are the processed view of the raw data from the source. According to BigML, each field is treated and serialized as per its type. You also get to see the processing errors such as missing values or data type mismatched values for each model. For each field, you can examine the data distribution and descriptive statistics. Learn more about datasets in BigML from this link. The dataset tab lists all the data sets that you own. It displays all the activities that you executed over the data set. So, when using BigML, you need not remember what models you created and which data set you used—a helpful feature for your daily experimentation with hundreds of models and when you can’t remember all of the related stuff.
- Supervised: Once you create models, all supervised models produced appear on this page. *NOTE* We’ll run through an example to create a supervised model shortly. Supervised models include the Ensembles, Classification, and Regression models.
- Unsupervised: Any unsupervised models created surfaces on this page. Unsupervised models supported in BigML include Clustering, Anomalies, Associations and Topic models.
- Predictions: This page displays the predictions performed over the models.
- Tasks: Each ML job you prepare appears on this page. You’re able to see the time taken to execute the tasks, the status, and various other statistics related to its execution from this page.
Practical Examples
Let’s practice with a data source provided in the BigML sample sources page and create a prediction model. We’ll use the Churn in the Telecom Industry data set. It is a dataset relating characteristics of telephony account features & usage to whether or not the customer churned. The source of the Churn Data Set in BigML is from Discovering Knowledge in Data: An Introduction to Data Mining. Alternatively, you can try uploading your own custom data. I was a bit too lazy to hunt down one of my own datasets in preparing this write-up, but would totally recommend uploading your own data at some point for some quick and useful experiments particular to your own collected data.
- To start with, select the Churn in the Telecom Industry data source as shown in the below illustration. This will show you the attributes, data types, and sample data instances.
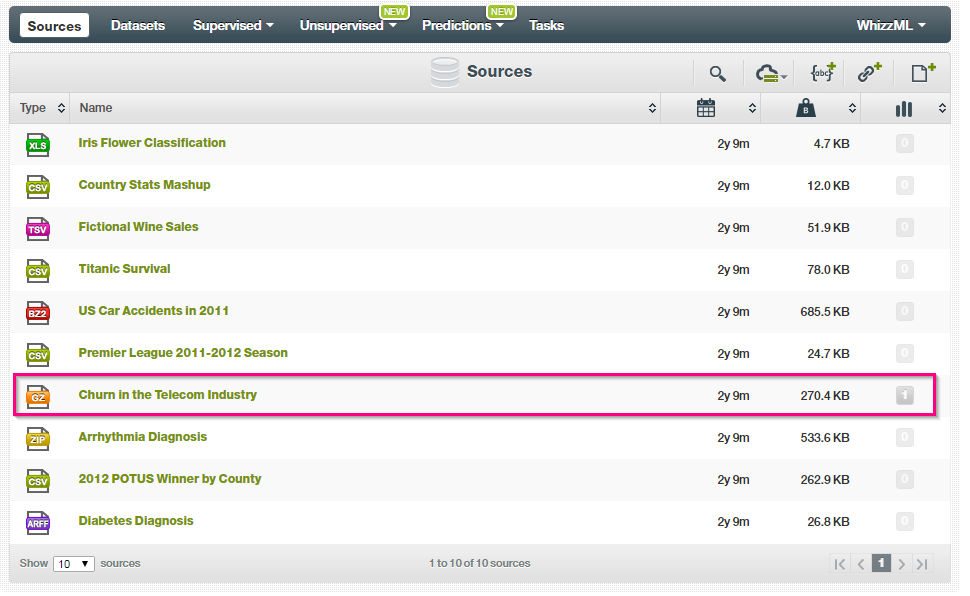
- We need to create a dataset from the source. Select the 1-Click Dataset from the list as shown below. This creates a Dataset from the raw telecom churn data. You can also try building the models directly. However, I always prefer to examine the data distributions and statistics before proceeding with own model creation.
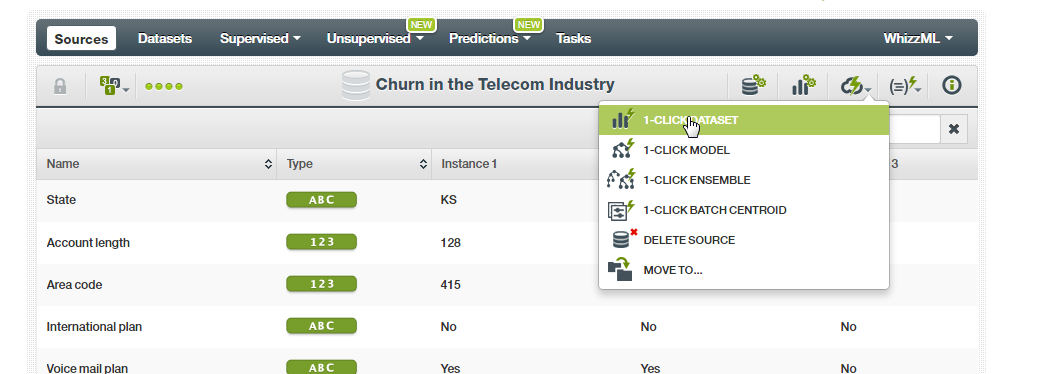
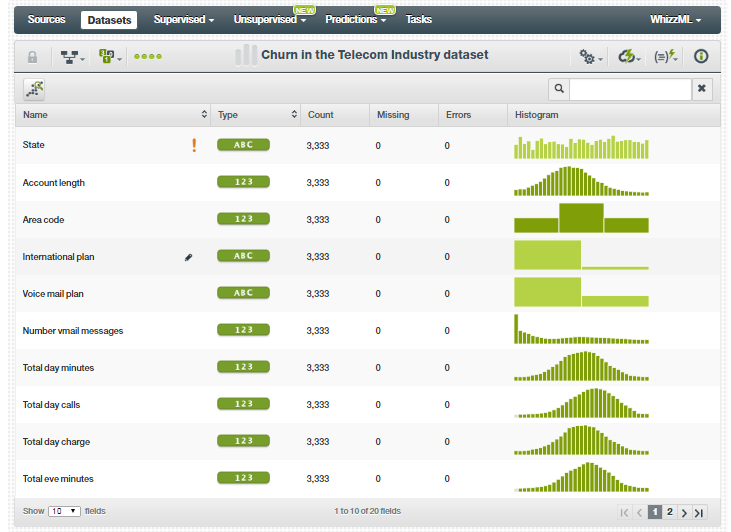
- Once you create a dataset, you can view most of the statistics of the attributes of that dataset.
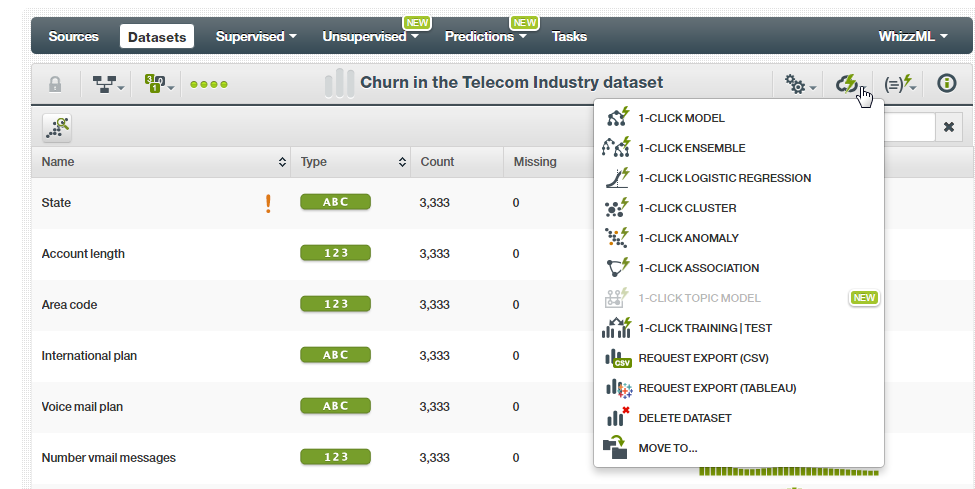
- Click on the icon as shown in the below illustration. You can see a list of operations that you’re able tp perform over this data set. Let’s take a simple route and create a model using the 1-click MODEL option. So, here we get one more advantage of using the BigML platform. The 1-click features hide the complexity of choosing the best parameters for a model and automate the model building process. Using this 1-click option, we can create a model without knowing the art of creating models. What we need to know are only the definitions of the models – Who does What.
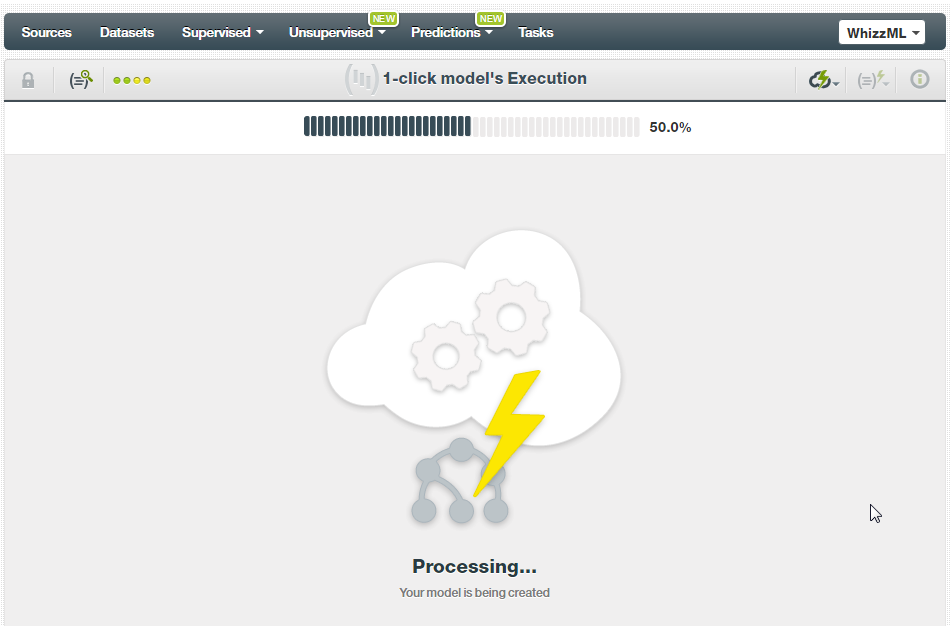
- An attractive screen shows the progress of the model creation. Now, you can sit back and grab a coffee while it prepares your model.
- Once the execution is finished, we see a rich decision tree with all required details for the model. If we hover the mouse over the nodes, we also notice the node statistics. There are various features to try out. For example, change the tree visualization to sunburst chart, download model summary reports, see the field importance, and much more.
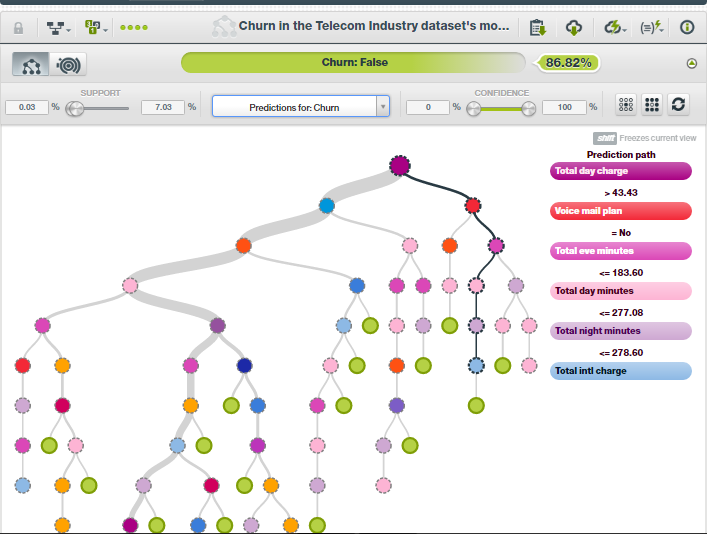
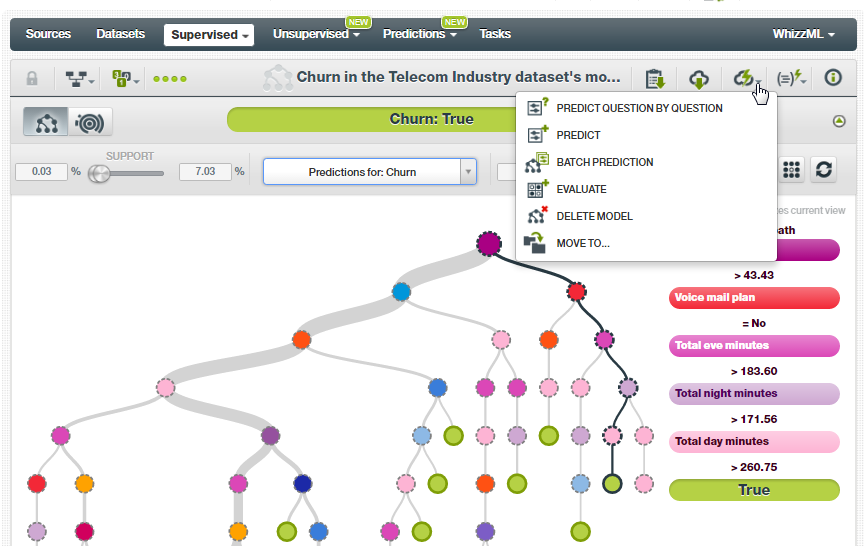
- If you are satisfied with the model, select the PREDICT option from the list as shown in the figure below. The list has many options for creating predictions from the model. You can also select PREDICT QUESTION BY QUESTION. A very useful feature where the system throws some questions at you and based on your answers it predicts whether the customer will churn. Similarly, you can try it out with BATCH PREDICTION if you have a bunch of customers with which you need to predict churn rate for.
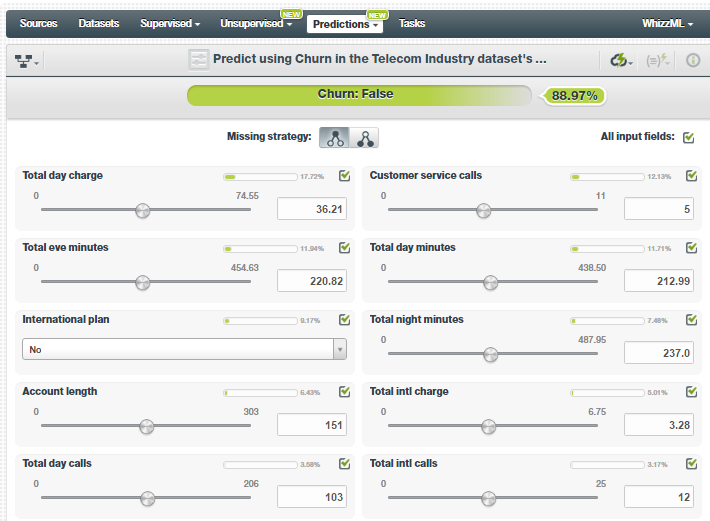
Now, once you get to the prediction screen, play with the dataset attributes to see when a customer will churn. For me, the initial page was showing Customer Churn as false. When I changed the value of the attribute Total eve minutes to 129.9, the Customer Churn turned true.
However, this is not all that is present in BigML, but just a small sampling. The features that stand out on this platform are:
- Interactive Visualization
- Various 1-click activity Options
- Machine Learning as a Service with flexible pricing
- Easy Development and Production Deployments
- Automation for Machine Learning using WhizzML
This was just an introduction to BigML. To learn more about the platform and get your hands dirty with it, create your account and check the documentation.
